Recently, the technical concept of blockchain is gradually heating up in the traditional IT circle, and it has become an alternative technical route for many legacy system upgrade and reconstruction plans. The author himself has been engaged in application system research and development for many years, and the performance of the system currently maintained is gradually showing bottlenecks. It is difficult to expand the shards and faces the potential demand for distributed improvement. Therefore, there is an urgent need for blockchain architecture technical reserves.
The key to improving the performance of the application system lies in the access management model (AAA, Authentication Authenticator, Authorization AuthorizaTIon, Accounting AccounTIng) on ​​the operation and maintenance side and the Concurrency/Throughput model on the business side. Blockchain is a typical "operation and maintenance-friendly" system, and its natural self-governance capabilities have greatly optimized the access management model. However, the concurrency/throughput model indicators of existing blockchain systems have been criticized. Whether it is BTC's 7tps or ETH's 40tps, it is difficult to raise its head in the face of traditional business systems with 10,000 or even 100,000 tps.
In line with the purpose of not recreating the wheel, first sort out the demand for blockchain projects:
·Focus on the underlying infrastructure, the project's own industry or field characteristics are not obvious, and it is easy to introduce the business of this industry;
·Able to realize micro-service level deployment, expansion friendly, easy to migrate and deploy;
·Concurrent throughput of 5k+, stable support of 10w DAU, strong reliability.
According to the needs, we can search for blockchain projects in a targeted manner. The search process is actually far simpler than imagined. There are so many blockchain projects, but there are not many projects that are purely technical frameworks that do not involve business scenarios or economic models. Through the project screening of mainstream exchanges (after all, you can't find an unstable team to do something), and basically delineated the EOS, QTUM, and AELF projects. The EOS official announcement throughput is about 3300~3500tps, and the QTUM official announcement throughput is ten times that of BTC (weighted and estimated to be 100tps). The AELF project released the testnet at the beginning of July, and the official has not yet released throughput information. The reason for selecting AELF as the research object is that the development guide has recently been released, and it has strong operability with the latest code version, and the Akka concurrency framework adopted by AELF has a wide range of applications and has had previous contacts.
Test designThe business processing capabilities of existing blockchain systems are generally built for value transfer, so the evaluation of the performance of the blockchain system should be oriented toward the transaction process. The main feature of the AELF project in the blockchain architecture is "main chain + multi-level side chain". There are special cross-chain algorithms between the chains to realize the coordination of resources between relatively isolated business units. The nodes in the chain are all running in the cluster. Internally, the throughput index is improved through parallelization scheme. According to the official information disclosed in the community, the testnet provides the test verification of the main chain parallel computing module in the early stage (that is, at present). After confirming the main chain performance, it can be upgraded to the multi-level side chain version in grayscale. This is reasonable from the perspective of the software quality system. of. Through participating in the technical live broadcast interaction in the community, I also fully discussed several technical solutions selected by AELF with the project technical team, especially the Akka parallel framework. Actively selecting mature technology elements that have been verified is indeed a commendable gesture when building new systems and new infrastructure, which further enhances the favorability of the AELF project. PS: The technical people of this team are also in the community, so NICE communicates very well.
TransacTIon, traditional IT people are accustomed to call "transactions", people in the blockchain circle are usually called "transactions", it may be inherited from the translation of the BTC white paper. Software evaluation should fully consider the requirements of the software quality system. Similarly, for the underlying architecture of a blockchain, transaction incentives that simulate the pressure of value transmission can be used as a form of verification of the tps indicators of the underlying infrastructure of the blockchain.
Based on this, first define an atomic transaction as the basic test case for this test verification-"contract transfer". One "contract transfer" includes two reads and two writes. The specific steps are as follows:
·Read the balance from account A (1 read);
·Read the balance from account B (1 read);
·Subtract the amount from account A (1 write);
·Increase the amount from account B (1 write).
Because I have been in touch with BTC before, I deeply admire the exquisite setting of Satoshi Nakamoto's UTXO system, but traditional application systems often rely on the account model system, so a classic atomic transfer transaction is selected as the standard test case, and the execution efficiency of this use case is used. As a basis for throughput indicators. AELF supports blockchain smart contracts, and the above atomic transactions must be written as contract scripts and deployed to the testnet.
Furthermore, define a basic test process outline:

This test process can be used as a typical blockchain performance evaluation strategy. Taking a "contract transfer" as a basic business execution unit, write a "contract script" program running on the blockchain platform, which can be deployed and executed by each node of the blockchain system. Before the implementation of the evaluation, the test data must be initialized according to specific use cases or randomly generated test cases. The evaluation of different scenarios and different rounds must be implemented based on the same test data to ensure the credibility of the test results. Test data is used as a transaction application to successively initiate incentives to the main network. For projects such as AELF that use distributed parallelization ideas for architectural design, multiple sets of data concurrent incentives can be used to test the blockchain system under high concurrent transaction scenarios. performance. During the test, the execution of the test case can be determined by real-time monitoring or specific time slice monitoring. The time slice can be set to N times the block generation period (N<=6, borrowing from the BTC mainnet 6 block confirmation convention) .
Continue to define different test scenarios:
·Scenario I: stand-alone scenario, 1 business processing node + 1 business data set;
·Scenario II: Cluster-single machine scenario, N business processing nodes + 1 business data set;
·Scenario III: Distributed cluster scenario, N business processing nodes + N business data sets.
The stand-alone scenario is designed to verify the independent performance of the blockchain system. Because the blockchain is a distributed cluster system, the evaluation and verification of the stand-alone scenario is not very meaningful for the final network performance index conclusion, but it helps us to better define The boundary of cluster testing. If the performance index of the stand-alone evaluation is P, the relationship between node/process growth and performance index growth can be used to determine whether it is necessary to conduct a larger-scale evaluation and verification when performing cluster evaluation. In addition, supplementing the test environment with network delays during the stand-alone test helps to quantify the factors affecting the network environment.
The cluster-single-machine scenario is designed to conduct coverage testing for the actual business types supported by the underlying blockchain platform. The blockchain technology itself is decentralized, but the upper-level business supported by the blockchain system may have the characteristics of centralization, so it is necessary to conduct a multi-to-one scenario simulation evaluation. This scenario is designed to quantitatively evaluate the business processing throughput of the blockchain system when there is a fixed bottleneck in the data I/O.
The distributed cluster scenario is designed to conduct coverage testing for business scenarios where both transaction execution processing and transaction data collaboration in the P2P network topology need to achieve blockchain consensus. This scenario is a typical blockchain system scenario. Through the evaluation of the stand-alone scenario and the cluster-single-machine scenario, it can assist us in comprehensive analysis of the test boundary and test difference factors in the scenario, and determine the test implementation method and the tested deployment The typicality of the environment leads to a more reliable evaluation conclusion.
The operation of the blockchain system has multiple levels. The blockchain program can be deployed to multiple servers, and each server can run multiple process-level instances (Workers). For AELF, each instance can be configured Multiple parallelized business units (Actors). Therefore, the performance index TPS is affected by the server, process, and business unit, and it needs to be reflected in the test. The optimal TPS evaluation result should be shown under a suitable server, process, and business unit configuration. Find the best value within the test conditions. Excellent configuration is also one of the purposes of this evaluation.
In summary, the testing and verification objectives to be achieved include, but are not limited to, concurrent execution capability under the operating state of a single service node and performance scalability under a cluster environment.
Test setup and deploymentThe environment selected for the test is a standard cloud platform virtual machine (including AWS and Alibaba Cloud). According to the official configuration recommended in the community, it uses a combination of 8vCPU+16G memory, a network bandwidth of 10G, Redis version 4.0.10, and Twemproxy version 0.4 .1. It is basically similar to the standard cluster production environment. The configuration may change with the increase of the test network content. The project technical team can get answers from the community at any time.
August 8th supplement: AELF official Github has given the authoritative version test construction steps, the following is the author's construction steps.
The core of developing and accessing the AELF testnet is to clarify the Benchmark environment. Through consultation and communication with the technical team, the following are the basic construction and deployment steps.
Clone and compile the code:
·Git clone https://github.com/AElfProject/AElf.git aelf
·Cd aelf
·Dotnet publish –configuration Release -o /temp/aelf
Confirm the configuration file directory:
·Mac/Linux: ~/.local/share/aelf/config
·Windows: C:\Users\xxxxx\AppData\Local\aelf\config
Configure data set information:
·Copy aelf/config/database.json in the code to the configuration file directory
·Modify the configuration according to the local Redis installation:
{
// Database type (memory: inmemory, Redis: redis, SSDB: ssdb)
"Type": "redis",
// Database address
"Host": "localhost",
// Database port
"Port": 6379
}
Single machine scenario deployment:
Copy the aelf/config/actor.json in the code to the configuration file directory, and configure IsCluster, WorkerCount, Benchmark, and ConcurrencyLevel according to the local situation:
{
// Is it a cluster mode
"IsCluster": false,
"HostName": "127.0.0.1",
"Port": 0,
// The number of parallel execution workers is recommended to be the same as the number of native CPU cores
"WorkerCount": 8,
// Run Benchmark mode
"Benchmark": true,
// Maximum parallel grouping level, greater than or equal to WorkerCount
"ConcurrencyLevel": 16,
"Seeds": [
{
"HostName": "127.0.0.1",
"Port": 32551
}
],
"SingleHoconFile": "single.hocon",
"MasterHoconFile": "master.hocon", "WorkerHoconFile": "worker.hocon",
"ManagerHoconFile": "manager.hocon"
}
Run Benchmark:
dotnet AElf.Benchmark.dll -n 8000 --grouprange 80 80 --repeattime 5
// -n total number of transactions--grouprange group range--repeattime number of repeated executions
Cluster scenario deployment:
Run ConcurrencyManager:
dotnet AElf.Concurrency.Manager.dll --actor.host 192.168.100.1 --actor.port 4053
// --The IP address of the actor.host Manager - The listening port of the actor.port Manager
Copy aelf/config/actor.json in the code to the configuration file directory, and configure IsCluster, HostName, WorkerCount, Benchmark, ConcurrencyLevel, Seeds according to the cluster situation:
{
// Is it a cluster mode
"IsCluster": true,
// Worker's ip address
"HostName": "127.0.0.1",
// Port that Worker listens to
"Port": 32551,
// The number of parallel execution workers is recommended to be the same as the number of native CPU cores
"WorkerCount": 8,
// Run Benchmark mode
"Benchmark": true,
// The maximum parallel grouping level, the number of processes greater than or equal to WorkerCount*Worker
"ConcurrencyLevel": 16,
// Manager's ip and port information
"Seeds": [
{
"HostName": "192.168.100.1",
"Port": 4053
}
],
"SingleHoconFile": "single.hocon",
"MasterHoconFile": "master.hocon",
"WorkerHoconFile": "worker.hocon",
"ManagerHoconFile": "manager.hocon"
}
Run ConcurrencyWorker:
dotnet AElf.Concurrency.Worker.dll --actor.port 32551
// --actor.port Worker's listening port
If the worker receives the welcome message from the Manager, it means that the worker has joined the cluster, and subsequent node expansion can be carried out based on this environment
Run Benchmark:
dotnet AElf.Benchmark.dll -n 8000 --grouprange 80 80 --repeattime 5
Test execution and data analysisThis part will not repeat the specific execution process, and directly give the dry goods of the test verification data for the three scenarios. It is especially emphasized that the data results of this test are tested by the author. The environment and process may not be very rigorous due to human operation errors. The specific performance indicators are subject to the official release, and those who do good things do not disturb! ! !
Scenario I Stand-alone scenario test data
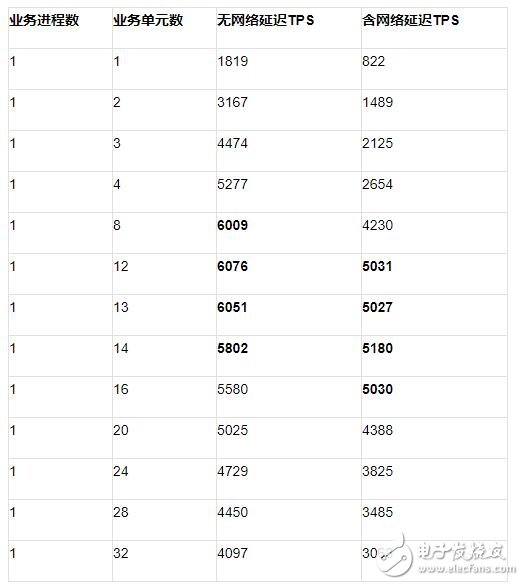
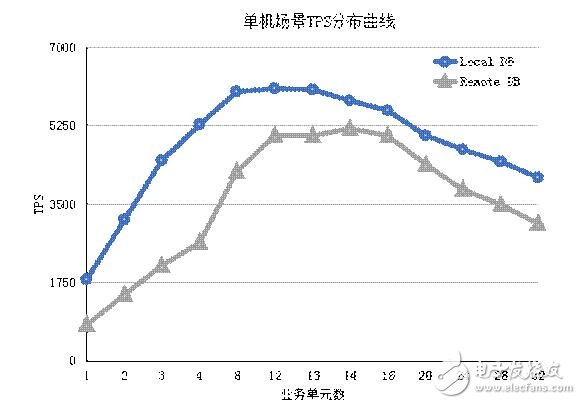
It can be seen from the above figure that when the database is deployed separately from the business unit, the network delay will cause the TPS indicator to drop, and the TPS indicator will follow the same trend under the same network delay.
Scenario II cluster-single machine scenario test data
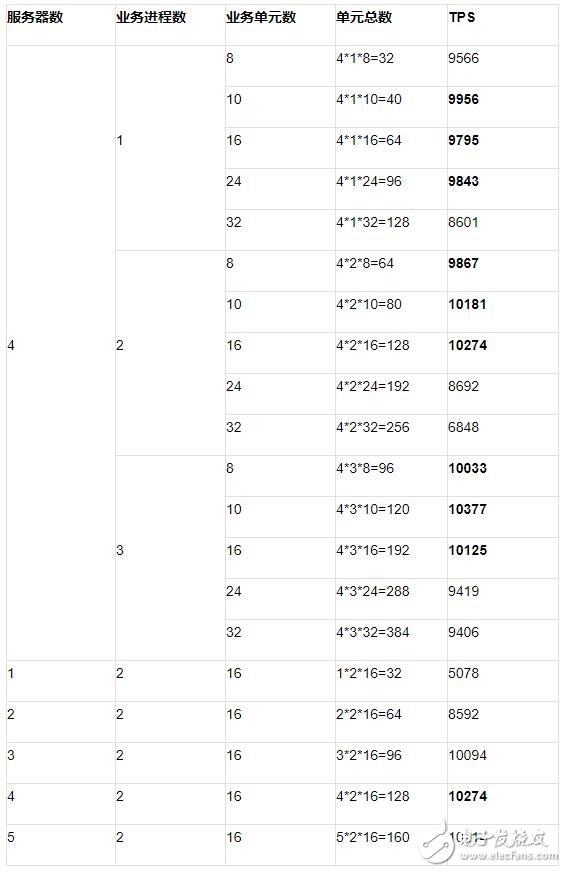
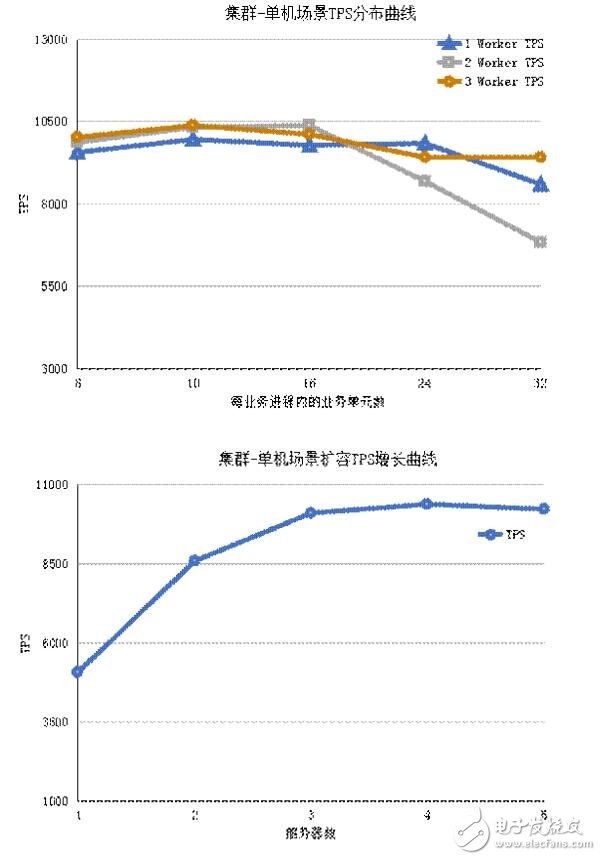
From the above two figures, it can be seen that when the data set service is deployed in a single case, the deployment mode of 2 processes and 16 business units is ideal. For the deployment model of 2 processes and 16 business units, a supplementary analysis of server expansion has been done. The analysis shows that when the data set service is a single instance, the performance of the server reaches the bottleneck when the server grows to 5, and the TPS indicator begins to decline.
Scenario III Distributed cluster scenario test data
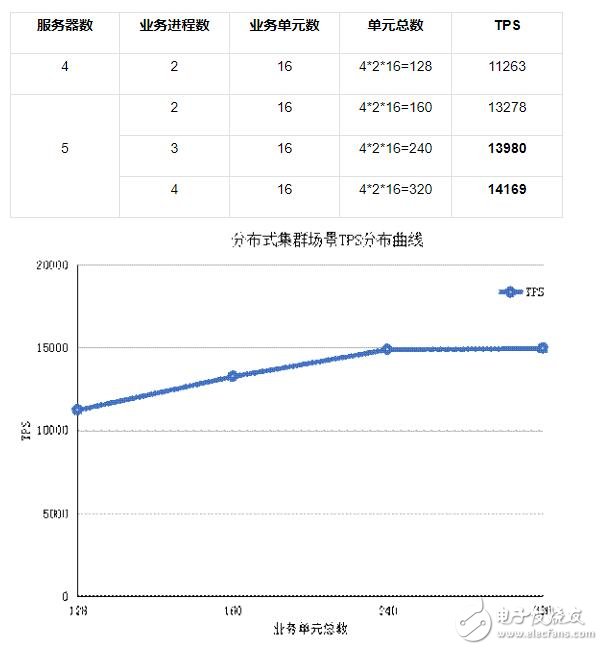
The test environment in the above figure is a cluster built with 8 Redis instances, 5 Twemproxy, and each server is connected to a different Twemproxy. The TPS indicator can grow to near the ideal value with the expansion.
Other relevant test parameters: use 240,000 transactions and repeat 5 times.
Test summaryThrough the execution results verified by the above test, it can basically be seen that with the expansion of the system, the growth of throughput performance indicators is relatively healthy, and the optimal indicator within the test range is expected to be about 1.3w~1.5w tps. In addition, in each set of specific deployment modes, an average performance improvement of about 10% to 15% can be obtained through system tuning. The extreme points of the throughput performance curve are in line with a reasonable level, which is in line with the rapid rise and slow fall of the Poisson distribution. . The current environment construction verification under small topology clusters can basically meet the throughput requirements of small and medium-sized business systems, and can be initially applied to the optimization and reconstruction of traditional application systems. Of course, it is inevitable that only blockchain technology is used for distributed databases and communication components. It's a little overkill, and we need to pay attention to the test situation of the multi-level side chain system in the follow-up, and further integrate the distributed business model.
After a simple test and verification, the author, who is also a brick-moving farmer, also has some suggestions to the AELF technical team:
When the transaction magnitude is large and the structure of the subsequent introduction of the side chain is more complicated, the current grouping strategy may be time-consuming and may be significantly improved. For example, when a 10w-level transaction is divided into a 1k-level processing unit group, the possible grouping time will reach 800ms ~1000ms, the grouping strategy needs to be further optimized under the subsequent multi-level side chain system;
The Round-Robin-Group routing strategy currently configured by the system is not optimal in the production environment, and the routing capability can be further improved through configuration and tuning;
In the process of parallel transaction processing, it is recommended to add a health monitoring mechanism, such as MailBox, to facilitate the operation and maintenance and development teams to understand the execution process and locate problems, otherwise the deadlock of complex related transactions may cause unforeseen system failure.
Excluding the above three points, the current performance of the test network is remarkable, and the follow-up progress is worth looking forward to. The above is the sharing of the plan for blockchain performance evaluation.
Ecome mobile radio,Portable Two Way Radio,Motorola Vhf Handheld Radio,Multi Band Portable Radio
Guangzhou Etmy Technology Co., Ltd. , https://www.gzdigitaltalkie.com