As a means of human-computer interaction, speech endpoint detection is of great significance in liberating human hands. At the same time, there are various background noises in the work environment. These noises can seriously degrade the quality of speech and thus affect the effectiveness of speech applications, such as reducing the recognition rate. With uncompressed voice data, network traffic in network interactive applications is large, which reduces the success rate of voice applications. Therefore, audio endpoint detection, noise reduction, and audio compression are always the focus of terminal voice processing and are still active research topics.
In order to get to know the basic principles of endpoint detection and noise reduction with you, take a glimpse of the mystery of audio compression. This time, guests of HKUST's senior R&D engineer Li Hongliang from the University of Science and Technology Beijing will give us a keynote speech: Detailed Explanation Hot spots in speech processing detection technology—endpoint detection, noise reduction, and compression.

Guest introduction
Li Hongliang graduated from the University of Science and Technology of China. HKUST's senior R&D engineers have long been engaged in the development of speech engines and voice-based cloud computing, one of the founders of HKUST's voice cloud, and led the research and development of voice encoding and decoding libraries on XFLY voice cloud platform. More than two billion. Dominant voice national standard body The department's construction has led and participated in the formulation of a number of national standards for speech. His share today will be divided into two major parts. The first part is endpoint detection and noise reduction, and the second part is audio compression.
Endpoint detection
Let's first look at Voice Activity Detection (VAD). Audio endpoint detection detects valid speech segments from continuous speech streams. It includes two aspects. The starting point of the effective voice is detected as the front end point, and the ending point of the effective voice is detected as the rear end point.
Endpoint detection of speech in speech applications is necessary. The first, very simple point, is to separate effective speech from continuous speech streams in the context of storing or transmitting speech, which can reduce the amount of data stored or transmitted. Secondly, in some application scenarios, the use of endpoint detection can simplify human-computer interaction. For example, in a recording scenario, the voice endpoint detection can omit the end of recording operations.

In order to more clearly illustrate the principle of endpoint detection, first analyze a piece of audio. The above figure is a simple audio with only two words. It can be seen from the figure that the amplitude of the sound wave in the head and tail mute part is very small, while the amplitude of the effective voice part is relatively large. The amplitude of a signal is intuitively expressed. The size of the signal energy: the energy value of the silent part is small, and the energy value of the effective speech part is relatively large. The speech signal is a one-dimensional continuous function that takes time as an independent variable. The computer-processed speech data is a sequence of sampled values ​​of the speech signal in time order. The size of these sample values ​​also represents the energy of the speech signal at the sampling point.

There are positive and negative values ​​in the sample values. It is not necessary to consider signs when calculating the energy value. From this point of view, it is a natural idea to use the absolute value of the sampled value to represent the energy value, since the absolute value sign is mathematically processed. It is inconvenient, so the energy value of the sampling point usually uses the square of the sampling value, and the energy value of a speech containing N sampling points can be defined as the sum of squares of the sampling values.
In this way, the energy value of a segment of speech is related to both the size of the sampled value and the number of sampling points contained therein. In order to examine the change of the speech energy value, it is necessary to first divide the speech signal according to a fixed duration such as 20 milliseconds. Each segmentation unit is called a frame, and each frame contains the same number of sampling points, and then the energy value of each frame speech is calculated.
If the energy value of the consecutive M0 frames in the front part of the audio is lower than a predetermined energy value threshold E0, and the energy value of the subsequent continuous M0 frame is greater than E0, the front end point of the speech is where the speech energy value increases. Similarly, if several successive frames of speech energy have large values ​​and the subsequent frame energy value becomes smaller and lasts for a certain period of time, it can be considered that the energy value decreases where it is the rear end of the speech.
The question is, how does the energy value threshold E0 take? What is M0? The ideal silent energy value is 0, so E0 in the above algorithm ideally takes 0. Unfortunately, there are often certain intensity background sounds in the scene where audio is collected. This simple background sound is certainly muted, but its energy value is obviously not 0. Therefore, the actual collected audio has a certain background sound. Basic energy value.
We always assume that the collected audio has a small segment of silence at the beginning, typically a few hundred milliseconds in length. This small segment of silence is the basis for our estimation of the threshold E0. Yes, this assumption is very important, assuming that the small segment of speech at the beginning of the audio is always muted! ! ! ! This assumption is also used in the introduction of noise reduction. When estimating E0, select a certain number of frames such as the first 100 frames of speech data (these are “muteâ€), calculate the average energy value, and then add an empirical value or multiply by a coefficient greater than 1, to obtain E0. This E0 is the criterion for judging whether a frame of speech is muted. If it is greater than this value, it is an effective speech, and if less than this value, it is a mute.
As for M0, it is easier to understand, and its size determines the sensitivity of the endpoint detection. The smaller the M0, the higher the sensitivity of the endpoint detection, and vice versa. Different scenarios for voice applications, the endpoint detection sensitivity should also be set to different values. For example, in voice-activated remote control applications, since voice commands are generally simple control commands, there is little chance of long pauses such as commas or periods in between, so it is reasonable to improve the sensitivity of endpoint detection. M0 is set to For small values, the corresponding audio duration is generally about 200-400 milliseconds. In a large segment of speech dictation applications, due to pauses in the middle such as a comma or a period, the endpoint detection sensitivity should be reduced. At this time, the M0 value is set to a relatively large value, and the corresponding audio duration is generally 1500-3000. millisecond. Therefore, the value of M0, which is the sensitivity of the endpoint detection, should be made adjustable in practice. The value of M0 should be selected according to the scenario of voice application.
The above is only a very simple general principle of voice endpoint detection. The actual application of the algorithm is far more complex than the above. As a widely used voice processing technology, audio endpoint detection is still a relatively active research direction. HKUST has used Recurrent Neural Networks (RNN) technology to perform voice endpoint detection. The actual effect can focus on the products of the company.
Noise reduction
Noise reduction is also called noise reduction. As mentioned above, the actual collected audio usually has a background sound with a certain intensity. These background sounds are generally background noise. When the background noise intensity is high, it will be applied to the voice. The effect has obvious influences, such as the decrease of speech recognition rate and the decrease of endpoint detection sensitivity. Therefore, it is necessary to perform noise suppression in the front-end processing of speech.
There are many types of noise, both spectrum-stable white noise and unstable pulse noise and fluctuating noise. In speech applications, stable background noise is the most common, and the technology is the most mature and the best. This course only discusses stable white noise. It is always assumed that the background noise spectrum is stable or quasi-stable.
The speech endpoint detection mentioned earlier is performed in the time domain, and the noise reduction process is performed in the frequency domain. To this end, we first briefly introduce or review the importance of the mutual conversion in the time domain and frequency domain. Tools - Fourier Transform.
To make it easier to understand, first look at the Fourier series learned in higher mathematics. The higher mathematics theory states that a function f(t) with a period of 2T that satisfies the Dirichlet condition can be expanded into a Fourier series:


For the general continuous time domain signal f(t), set its domain to [0, T]. After performing the singular extension, the Fourier series is as follows:
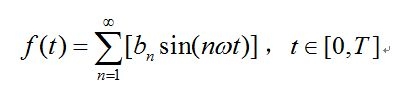
The calculation of bn is the same as above. From the above equation, any continuous time domain signal f(t) can be formed by a set of trigonometric functions. Or, f(t) can be infinitely approximated by a sequence of linear combinations of trigonometric functions. The Fourier series of the signal shows the frequency of the constituent signals and the amplitude at each frequency. Therefore, the right end of the equation can also be seen as the frequency spectrum of the signal f(t), which is more straightforward and the spectrum of the signal. It refers to the frequency components of this signal and the amplitude of each frequency. The left-to-right process of the above equation is a process of finding the spectrum of a known signal. The process from right to left is a process of reconstructing the signal from the spectrum of the signal.
Although the concept of frequency spectrum is easily understood by the Fourier series of the signal, in the actual calculation of the spectrum of the signal, a generalized version of the Fourier series, the Fourier transform, is used.
The Fourier transform is a large family. There are different forms in different fields of application. Here we only give two forms: the continuous form of the Fourier transform and the discrete Fourier transform:
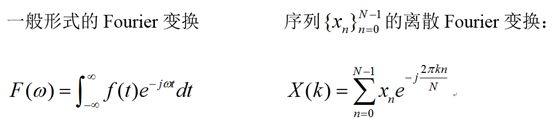
Where j is an imaginary unit, which is jj=-1, and its corresponding inverse Fourier transform is:

In practical applications, the spectrum of the signal can be obtained after Fourier transforming the digitally sampled signal. After the processing in the frequency domain is completed, the inverse Fourier transform can be used to convert the signal from the frequency domain to the time domain. Right, the Fourier transform is an important tool that can complete the conversion from the time domain to the frequency domain. After a signal is Fourier transformed, the spectrum of the signal can be obtained.
The above is a brief introduction to the Fourier transform. It is irrelevant for a friend with a poor mathematics background to understand it. As long as it is clear that a Fourier transform of the time domain signal can obtain the spectrum of this signal, the following conversion is completed:

The left side is the time domain signal, and the right side is the corresponding spectrum. The time domain signal is generally concerned with what time the value is taken. The frequency domain signal is concerned with the frequency distribution and amplitude.
With the above theory as a basis, it is easier to understand the principle of noise reduction. The key to noise suppression is to extract the spectrum of noise, and then use the inverse noise compensation algorithm to calculate the spectrum of the noise. After the voice. This sentence is very important, and the content behind it is developed around this sentence.
The general process of noise suppression is shown in the figure below:

Similar to the endpoint detection, assuming that a small segment of speech at the beginning of the audio is a background sound, this assumption is very important because this small background sound is also the background noise and is the basis for extracting the noise spectrum.
Noise reduction process: First, the small background sound is divided into frames, and grouped according to the order of the frames. The number of frames in each group may be 10 or other values, the number of groups is generally not less than 5, and then the background of each group The noise data frame uses the Fourier transform to obtain its spectrum, and after averaging the spectra, the spectrum of the background noise is obtained.
After the spectrum of noise is obtained, the noise reduction process is very simple. The red part in the figure on the left of the figure above is the spectrum of noise, and the black line is the spectrum of the effective speech signal. Both of them form the spectrum of the noisy speech. After deducting the noise spectrum from the spectrum of the noisy speech, the spectrum of the denoised speech is obtained, and then the inverse Fourier transform is used to switch back to the time domain, thereby obtaining denoised speech data.
The figure below shows the effect of noise reduction
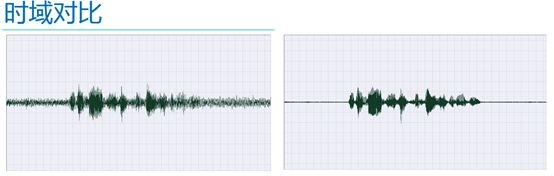
The left and right graphs are the comparisons in the time domain before and after noise reduction. The left side is a noisy speech signal. The noise can be seen clearly from the figure. On the right is the noise-reduced speech signal. It can be seen that the background noise is greatly suppressed.
The following two figures are in the frequency domain
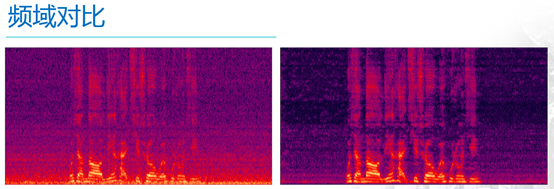
The horizontal axis represents the time axis, the vertical axis represents the frequency, the left is the noisy speech, and the bright red portion is the effective speech, while those in the purple color like sand are the noise. It can be seen from the figure that the noise is not only “omnipresent,†but also “everywhereâ€, that is, it is distributed at various frequencies, and the right side is the noise-reduced voice, which can be clearly seen. Out of the noise, those parts of the purple that were like sand before noise reduction were a lot lighter, and noise was effectively suppressed.
In practical applications, the noise spectrum used by noise reduction is usually not fixed, but it is continuously modified as the noise reduction process proceeds, ie, the process of noise reduction is adaptive. The reason for this is that on the one hand, the mute length of the front part of the speech data is not always long enough. The lack of background noise data often results in an inaccurate noise spectrum. On the other hand, the background noise is often not absolutely stable, but is gradually changing or even mutating. To another stable background noise.
These reasons all require that the used noise spectrum be modified in time during noise reduction to obtain better noise reduction effects. The method to modify the noise spectrum is to use the mute in the subsequent audio, repeat the noise spectrum extraction algorithm, get a new noise spectrum, and use it to correct the noise spectrum used for noise reduction, so the endpoint detection is still used in the process of noise reduction . How to judge silence. The method of noise spectral correction is either weighted averaging of new and old spectra, or the use of new noise spectra to completely replace the noise spectrum in use.
The above is a very simple principle of noise reduction. The noise reduction algorithm in practical applications is far more complicated than the one described above. The noise sources in reality are various and the mechanism and characteristics of the noise generation are also more complicated. Therefore, noise suppression is still a relatively active research field in today's world. New technologies are also emerging. For example, multi-microphone arrays have been used for noise suppression in practical applications.
Audio compression
The need for audio compression is well known and will not be repeated. All audio compression systems require two corresponding algorithms, one is an encoding running on the source, and the other is a decoding running on the receiving end or user terminal.
The encoding and decoding algorithms show some asymmetry. One such asymmetry is that the efficiency of the encoding algorithm and the decoding algorithm can be different. Audio or video data is usually encoded only once, but it will be decoded thousands of times, so the encoding algorithm is more complex, less efficient, and expensive, but the decoding algorithm must be fast and simple. cheap. The asymmetry of encoding and decoding algorithms also indicates that the encoding and decoding process is usually irreversible, that is, the data obtained after decoding and the original data before encoding may be different as long as they sound or appear to be The same can be, this codec algorithm is usually called lossy, and corresponding to this, if the data obtained after decoding is consistent with the original data, this encoding and decoding is called lossless.
Audio and video encoding and decoding algorithms are mostly lossy, because tolerate the loss of some small amount of information, can often be replaced by a substantial increase in the compression ratio, the audio signal compression coding uses some of the data encoding technology, such as entropy coding, waveform coding, Parameter coding, mixed coding, perceptual coding, etc.
This lesson focuses on perceptual coding. Compared to other coding algorithms, perceptual coding is based on some features of the human auditory system (psychoacoustics) and removes redundancy in the audio signal to achieve audio compression. Compared to other audio encoding algorithms (lossless), a large compression ratio of 10 times or more can be achieved without the human ear experiencing significant distortion.
First, we introduce the psychoacoustic basis of perceptual coding. The core of audio compression is to remove redundancy. The so-called redundancy is the information contained in the speech signal that cannot be perceived by the human ear. It does not help human beings to determine information such as timbre and tone. For example, the human ear can hear a sound in the frequency range of 20-20 kHz and cannot perceive the low frequency. Infrasound at 20Hz and ultrasound at frequencies above 20KHz. For another example, the human ear cannot hear a sound that is "not loud enough." Perceptual coding is the use of such features of the human hearing system to achieve the purpose of removing audio redundant information.
The psychoacoustics in perceptual coding mainly include: frequency masking, time domain masking, audibility threshold, and the like.

Frequency-shielded frequency masking can be seen everywhere in life. For example, you sit quietly watching TV at home on the sofa. Suddenly, the sound of a very harsh electric drill drilled at a neighbor's house is coming. You can hear it now. Only the strong noise emitted by hand drills, although the sound produced by the television is still stimulating your eardrum, but you turn a deaf ear, that is, a high-intensity sound can completely shield a lower intensity sound This phenomenon is called frequency masking.

Time domain shielding undertakes the previous example. Not only the human ear couldn't hear the sound of the TV within the time the electric drill made a sound, but even if the sound of the electric drill just stopped, the human ear could not hear the sound of the TV. This phenomenon is called time domain masking. The reason why time domain masking occurs is that the human auditory system is a gain-adjustable system. When the sound is louder, the gain is lower, and when the sound is low, the gain is higher. Sometimes humans even use external means to change the gain of the auditory system, for example, to avoid hearing the eardrum from loud sounds, and to hold the breath, side ear, and then listen to weaker sounds. . In the above example, when the loud sounds just disappeared, the auditory system needed a short period of time to increase the gain. It was during this short period of time that the time domain mask was generated.
The following is the audibility threshold, which is often important for audio compression.
Imagine that in a quiet room, a computer-controlled speaker can emit sound at a certain frequency, and at the beginning, the speaker power is low, and a person who is at a certain distance from a normal hearing person cannot hear the sound from the speaker. Then start gradually increasing the power of the speaker. When the power is increased to just be audible, record the power of the speaker (level, in dB). This power is the audibility threshold at this frequency.
Then change the frequency of the audio frequency emitted by the speaker and repeat the above experiment. The curve of the final audible threshold value with frequency is shown in the figure below:

It can be clearly seen from the figure that the human auditory system is most sensitive to sounds in the frequency range of 1000-5000 Hz. The closer the frequency is to the two sides, the slower the human hearing response is.
Looking back at the frequency masking situation, this experiment adds a signal with a frequency of 150 Hz and a strength of 60 dB to the room, and then repeats the experiment. The experimentally obtained audible threshold curve is shown in the following figure:
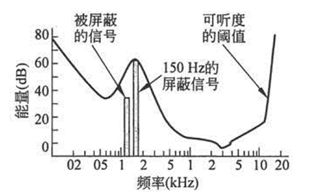
As is evident from the figure, the audibility threshold curve is strongly distorted around 150 Hz and is greatly increased upwards. This means that the sound of a certain frequency near 150 Hz which is originally located above the audibility threshold may become inaudible due to the presence of a stronger signal of 150 Hz, that is, it is shielded.
The basic rule of perceptual coding is that there is never a need to encode a signal that cannot be heard by the human ear. Simply put, the signal that cannot be heard does not require coding. This nonsense is precisely one of the focuses of speech compression research. Another meaning of nonsense is that it is very easy to understand the correct words. Closer to home, what can't be heard? Signals or components whose power is lower than the audibility threshold, masked signals or components, which are not heard by human ears, are all mentioned above as "redundancy".
The above is some of the things in my heart. To understand audio compression well, you need to understand a more important concept: subbands. A subband refers to such a frequency range. When the frequencies of two tones are within one subband, one will hear two tones. More generally, if the frequency distribution of a complex signal is within one sub-band, the human ear feels that the signal is equivalent to a simple signal whose frequency is at the center frequency of the sub-band, which is the core connotation of the sub-band. . In simple terms, a subband refers to a range of frequencies, and signals with a spectrum within this range can be replaced by a single frequency component.

The frequency of the sub-band is taken as an equivalent frequency, and the amplitude takes the weighted sum of the amplitudes of the frequency components within the sub-band. A simpler method is to directly add the amplitudes of the frequency components as the amplitude of the equivalent signal. The frequency components in the range can be replaced with one component.
Let the frequency of the spectrum of a signal be the lowest value w0 and the maximum value w1. Subband coding divides the frequency range between w0-w1 into several subbands, and then the components in each subband range are replaced by an equivalent frequency component. In this way, a signal with a complex spectrum can be equivalent to a spectrum that constitutes a very simple signal—the spectrum is greatly simplified and there is very little that needs to be stored.
It is not difficult to know from the above process how the subbands have a great influence on the quality of the compressed audio (after all, it is approximately equivalent). The subband division method is a very important topic for subband coding, which can be broadly divided into equal-width subband coding and widening subband coding.
The difference in the number of subbands after the subband division leads to different levels of compression algorithms. It is easy to know that the lower the code rate is, the higher the compression rate is, and the less the number of sub-bands is, and the sound quality is worse. The opposite situation is also easy to understand.
Understand the subband coding, audio compression is very easy to understand, a signal through a set of triangular filters (equivalent to a group of subbands), is reduced to a small number of frequency components. Then consider the direct disregard of these frequency components, energy or amplitude, below the audibility threshold curve (delete the component because it cannot be heard). Then examine the remaining two or two adjacent frequency components. If one of them is masked by the next frequency, it is also deleted. After the above processing, the frequency components contained in the spectrum of a complex signal are very simple, and these information can be stored or transmitted using very little data.
The inverse Fourier transform is used to reconstruct the simple spectrum obtained above into the time domain to obtain the decoded speech.
The above is the simple principle of audio compression. Let's talk about the audio codec library.
There are many open source audio codecs that can be publicly available, and their features and capabilities are different, as shown below:

It can be seen from the figure that AAC and MP3 take the "high end route" to encode high sampling rate music, while AMR and SPEEX take the middle and low end routes and can handle the following 16K sampling rate Voice signals, which are sufficient for speech applications such as speech synthesis, speech recognition, and voiceprint recognition.
HKUST's voice cloud uses the SPEEX series. The relevant information of the algorithm is shown in the figure below:

Speex encoding and decoding library has a wide range of compression ratio conversion and a wide range of compression levels to choose from, so it is very suitable for application in mobile terminals where network conditions are more complex.
Well, the above is the entire content of this lesson.
summary:
Audio endpoint detection, noise reduction, and voice compression, many people find mysterious, difficult to understand and difficult to grasp. However, as a result of Li’s speech, I often feel that the voice processing technology on the tall is also spoken in depth. Originally, the key to these technologies can be understood without the need for profound theoretical foundations: The key to audio endpoint detection is to determine the scale used to distinguish between mute and effective speech based on the previous silence. The key to noise reduction is to use a small background noise in front of it. To extract the spectrum of noise, one of the audio compression methods is to make full use of human heart acoustics, divide subbands, remove redundancy, etc.
Let us focus on the latest developments in voice processing technology in the above areas.
(If you are interested in the products and technologies of HKUST, please visit the official website of HKUST.)

48V Power Battery,Lithium Ev Battery,Power Lithium Battery,Customized Lithium Battery
Sichuan Liwang New Energy Technology Co. , https://www.liwangnewenergy.com