CNN is able to categorize images, but how to identify specific parts of the image is a world problem before 2015. Jonathan Long, the neural network god, published "Fully ConvoluTIonal Networks for SemanTIc SegmentaTIon" and dug a pit in the semantic segmentation of images, so that endless people jumped into the pit.
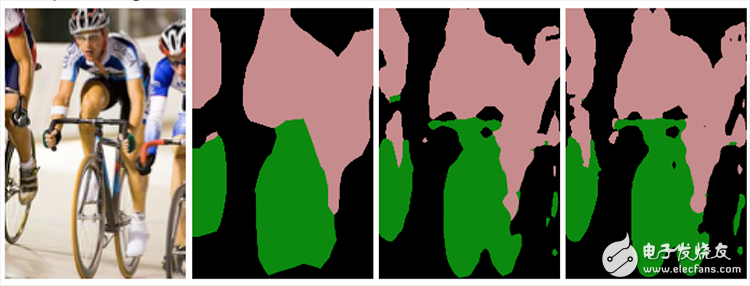
Full Convolution Network Fully ConvoluTIonal Networks
CNN and FCN
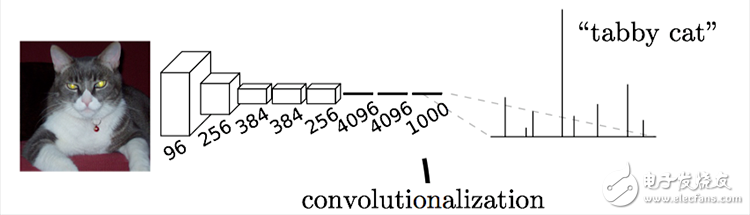
Usually, the CNN network is connected to a number of fully connected layers after the convolutional layer, and the feature map generated by the convolutional layer is mapped into a fixed length feature vector. The classic CNN structure represented by AlexNet is suitable for image-level classification and regression tasks, because they finally expect a numerical description (probability) of the entire input image. For example, AlexNet's ImageNet model outputs a 1000-dimensional vector indicating that the input image belongs to The probability of each class (softmax normalization).
Chestnut: The cat in the picture below, enter AlexNet, and get an output vector of length 1000, indicating the probability that the input image belongs to each class, and the statistical probability of “tabby cat†is the highest.
The FCN classifies the image at the pixel level, thereby solving the problem of semantic segmentation of the semantic level. Unlike the classic CNN, which uses a fully connected layer to obtain a fixed-length feature vector for classification after the convolutional layer (full-coupling layer + softmax output), the FCN can accept input images of any size, using the deconvolution layer for the last convolutional layer. The feature map is upsampled to restore it to the same size of the input image, so that a prediction can be generated for each pixel while preserving the spatial information in the original input image, and finally on the upsampled feature map Pixel classification.
Finally, the loss of the softmax classification is calculated pixel by pixel, which is equivalent to one training sample per pixel. The following figure shows the structure of the Full Convolutional Network (FCN) used by Longjon for semantic segmentation:
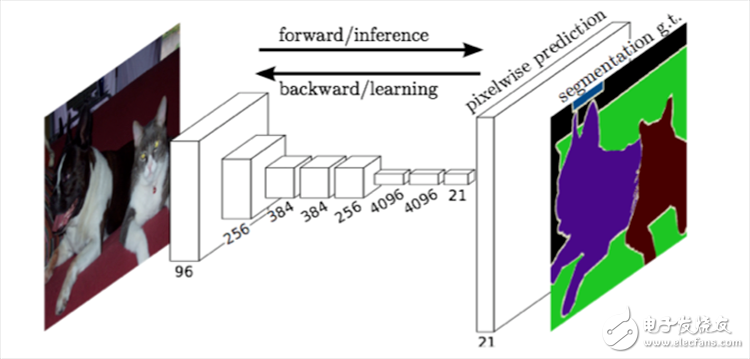
To put it simply, the FCN and CNN regions are replaced by a convolutional layer at the last fully connected layer of CNN, and the output is a good image of Label.
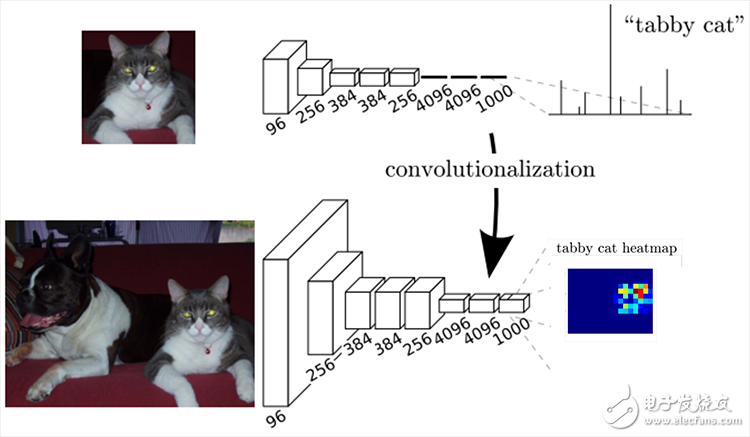
In fact, the power of CNN is that its multi-layer structure can automatically learn features, and can learn multiple levels of features: shallower convolutional layer sensing domain is smaller, learn some local area features; deeper The convolutional layer has a large perception domain and is able to learn more abstract features. These abstract features are less sensitive to the size, position, and orientation of the object, helping to improve performance. The following diagram shows the CNN classification network:
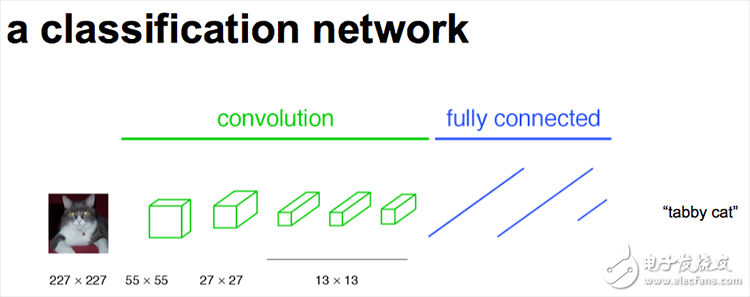
These abstract features are very helpful for classification, and can well determine what kind of objects are contained in an image, but because of the details of some objects, the specific contour of the object cannot be given well, and each pixel is pointed out. Which object belongs to it, so it is very difficult to achieve accurate segmentation.
Traditional CNN-based segmentation method: In order to classify a pixel, an image block around the pixel is used as input to the CNN for training and prediction. This method has several disadvantages: First, the storage overhead is large. For example, the size of the image block used for each pixel is 15x15, and then the window is continuously slid. Each time the sliding window is discriminated and classified by the CNN, the required storage space is sharply increased according to the number and size of the sliding window. Second, the calculation efficiency is low. Adjacent blocks of pixels are essentially repetitive, and convolution is calculated one by one for each block of pixels, and this calculation is largely repetitive. Third, the size of the pixel block limits the size of the perceived area. Usually the size of a pixel block is much smaller than the size of the entire image, and only some local features can be extracted, resulting in limited performance of the classification.
The Full Convolutional Network (FCN) recovers the categories to which each pixel belongs from abstract features. That is, the classification from the image level is further extended to the classification at the pixel level.
Fully connected layer -> into a convolution
The only difference between the fully connected layer and the convolutional layer is that the neurons in the convolutional layer are only connected to one local region in the input data, and the neurons in the convolutional column share parameters. However, in both types of layers, neurons are all calculated point products, so their functional form is the same. Therefore, it is possible to convert the two into each other:
For any convolutional layer, there is a fully connected layer that implements the same forward propagation function as it does. The weight matrix is ​​a huge matrix, except for some specific blocks, the rest are zero. In most of these blocks, the elements are equal.
Instead, any fully connected layer can be converted to a convolutional layer. For example, a fully connected layer of K=4096, the size of the input data body is 7?7?512, this fully connected layer can be equivalently regarded as an F=7, P=0, S=1, K=4096 Convolutional layer. In other words, the size of the filter is set to match the size of the input data volume. Since there is only a single depth column overlaid and slipped over the input data body, the output will become 1?1?4096, which is the same as using the initial fully connected layer.
airpods case
airpods case
Guangzhou Ysure Electronic Technology Co., Ltd. , https://www.ysurecase.com