Recently, DeepMind proposed a hyperparameter optimization method in the paper Based on Training Based on Neural Networks. While using the parallel training of traditional random search, the inspiration from the GA algorithm introduces the practice of copying parameter update iterations from other individuals. The effect is remarkable. According to the official, the use of this method called PBT can greatly improve the efficiency of computer resource utilization, the training is more stable, and the model performance is better.

From Go to Atari games to image recognition and language translation, neural networks have achieved great success in all fields. But often overlooked, the success of neural networks in specific applications often depends on a range of choices made at the start of the study, including what type of network, training data, and training methods are used. Currently, the selection of these choices (hyperparameters) is based primarily on experience, random search, and computer-intensive search.
In a recent paper published by DeepMind, the team proposed a new method of training neural networks, Population Based Training (PBT, which is a group-based training), which can help by simultaneously training and optimizing a series of networks. Developers quickly choose the best hyperparameters and models.
This method is actually the integration of the two most commonly used hyperparameter optimization methods: random search and hand-tuning. If a random search is used alone, the neural network population is trained in parallel and the best performing model is selected at the end of the training. In general, this means that only a small group of people can receive good hyperparameter training, and most of the remaining training is of poor quality, basically just wasting computer resources.
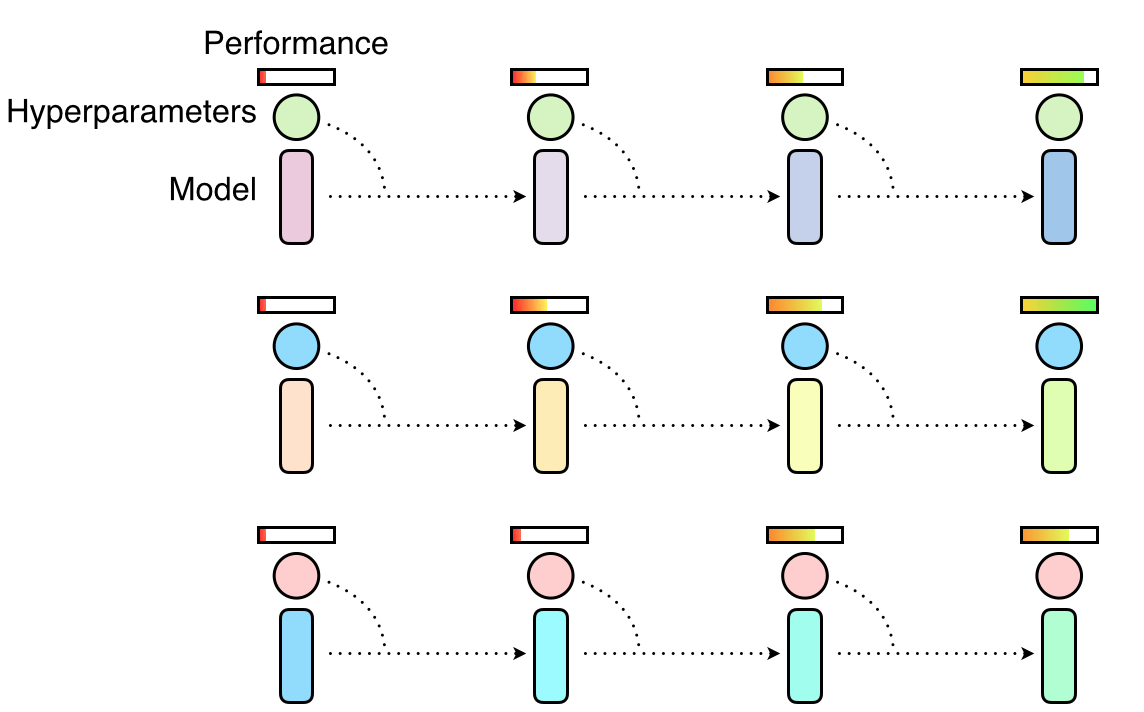
The random search selects the hyperparameters, and the hyperparameters are trained in parallel and independent. Some hyperparameters may help build a better model, but others won't
If manual debugging is used, the researcher must first speculate which superparameter is most appropriate, then apply it to the model, and then evaluate the performance, so that it cycles back and forth until he is satisfied with the performance of the model. While doing so can achieve better model performance, the disadvantages are equally striking, that is, it takes too long, sometimes it takes weeks or even months to complete the optimization.
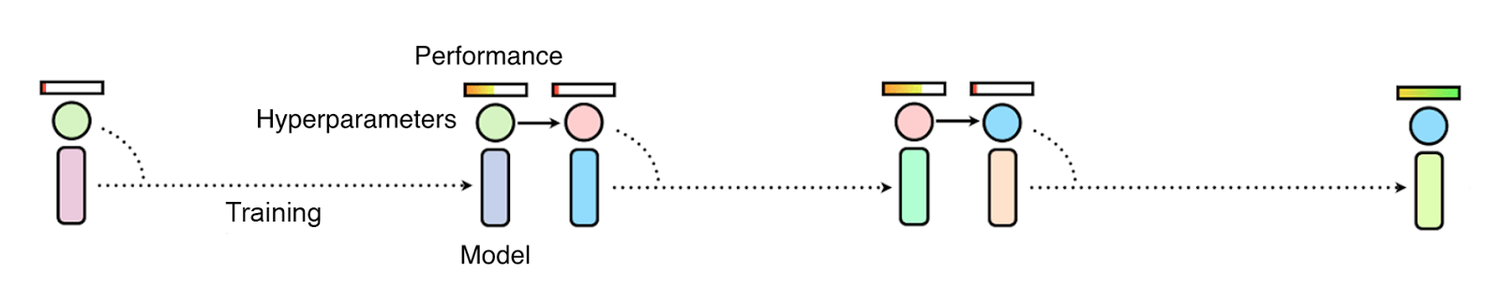
If you use manual debugging or Bayesian optimization to select hyperparameters by observing the training effects in turn, the overall progress will be abnormally slow.
PBT combines the advantages of both methods. Like random search, it first trains a large number of neural networks for random hyperparameter experiments, but the difference is that these networks are not independently trained, they will continuously integrate the information of other hyperparameter groups to self-improve and concentrate computing resources. Give the most promising models. This inspiration comes from the genetic algorithm (GA), in which each individual (candidate solution) can be iterated by using parameter information of other individuals, for example, an individual can replicate a parametric model from another better performing individual. Similarly, PBT encourages each hyperparameter to explore the formation of new hyperparameters by randomly changing the current value.
With the deepening of the training of neural networks, the process of development and exploration is carried out on a regular basis to ensure that all hyperparameters have a good basic performance, and new hyperparameters are constantly being formed. This means that PBT can quickly select high-quality hyperparameters and put more training time into the most promising models. The most important thing is that it also allows the hyperparameters to be adjusted during training to automatically learn the best configuration. .
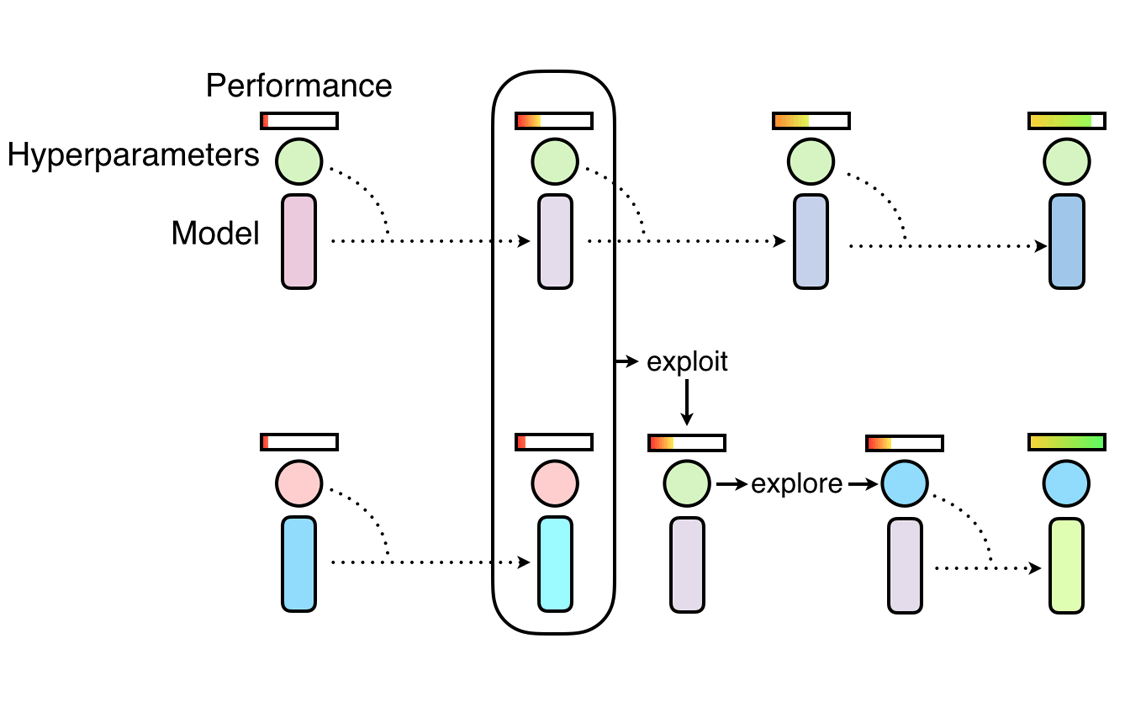
PBT neural network training begins with random search, but allows individuals to take advantage of partial results from other individuals and explore new hyperparameters as they progress through training
To test the effects of PBT, DeepMind did some experiments. For example, the researchers tested a set of challenging learning problems with the most advanced methods on the DeepMind Lab, Atari and StarCraft II game platforms. Experiments have shown that in all cases, PBT is trained to be stable and quickly finds the best hyperparameters, providing results that exceed the latest baseline.
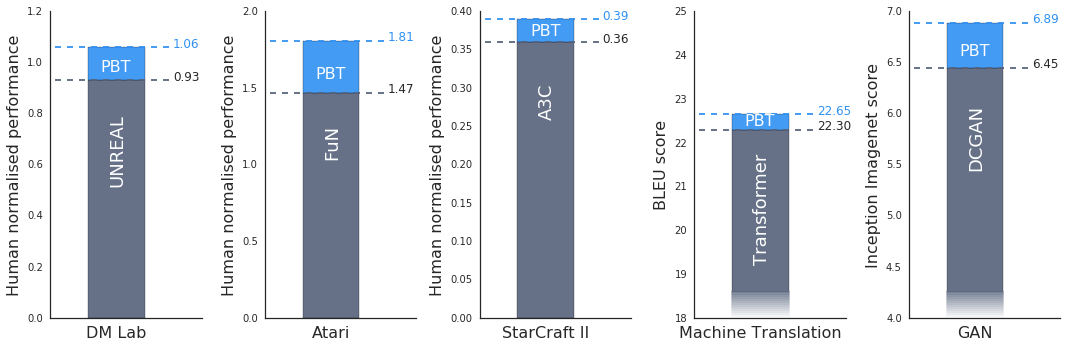
They also found that PBT is equally applicable to generating a confrontation network (GAN). In general, GAN's hyperparameters are difficult to debug, but in one experiment, DeepMind's PBT framework brought the model's Inception Score to a new high, jumping from 6.45 to 6.89 (the last image above) Shown).
PBT also experimented on Google's machine translation neural network. As Google's most advanced machine tool, the ultra-parameter optimization method used by these neural networks is manual debugging, which means that they need to be trained for several months according to the researcher's well-designed hyper-parameter schedule before being put into use. Using PBT, the computer automatically establishes a timetable. The model performance obtained by the training program is similar to or better than the current method, and a satisfactory model can be obtained with only one training.
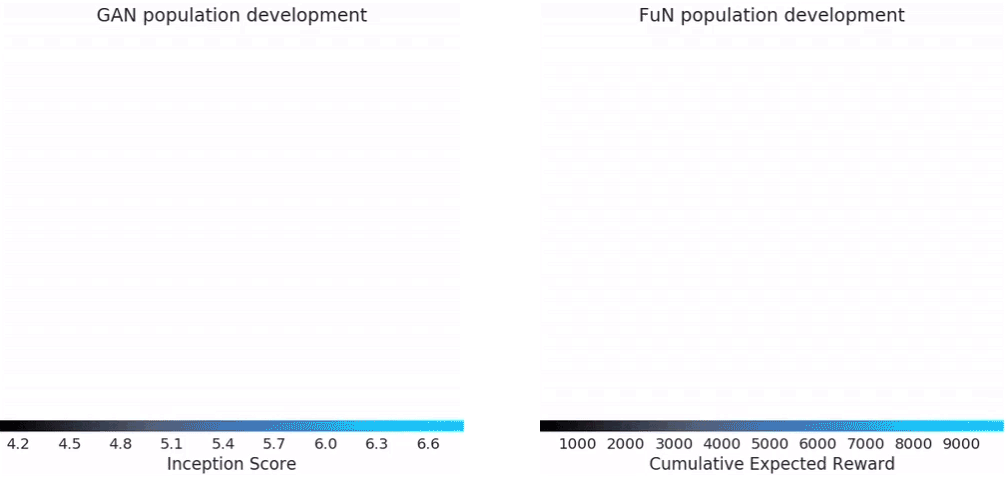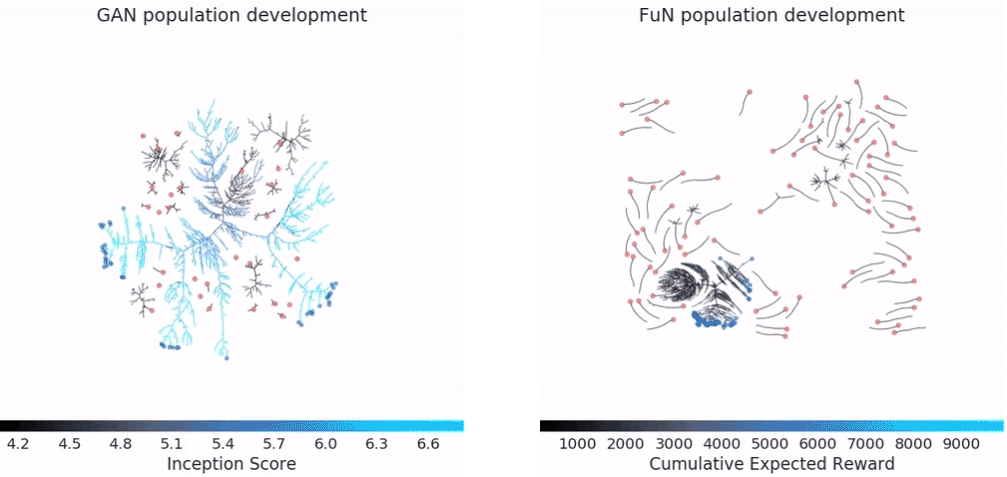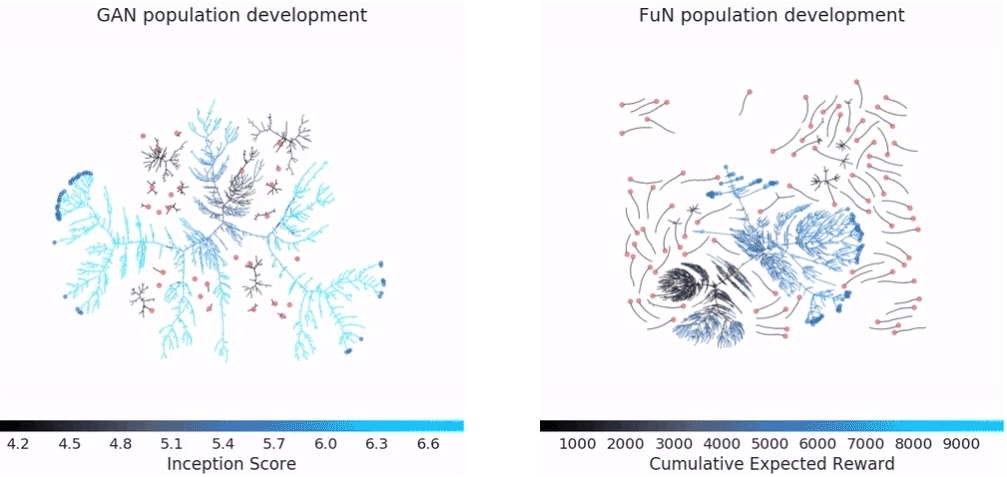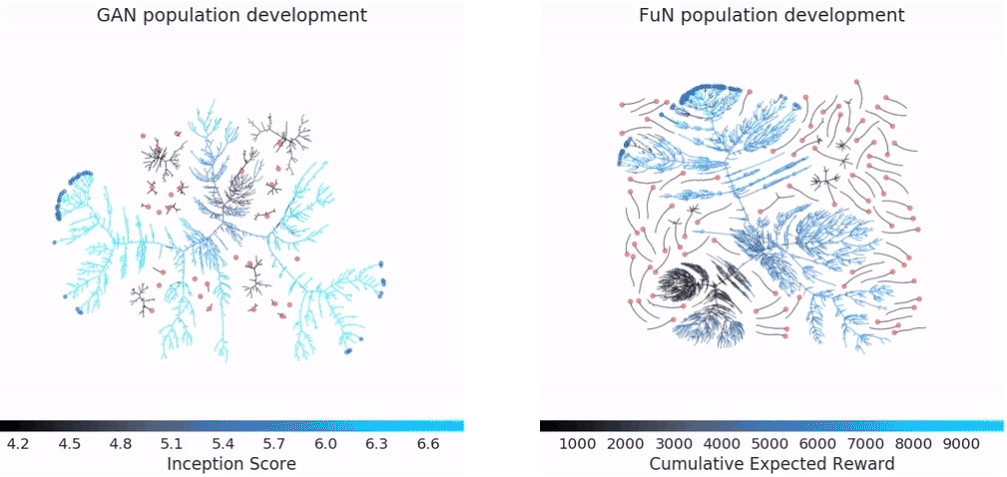
PBT performance on GAN and Atari game "Pacman": pink point is the first generation, blue point is the last generation, branch represents the operation has been performed (parameters have been copied), the path indicates the continuous update of the steps
DeepMind believes that this is just the beginning of a new parametric optimization approach. According to the comprehensive paper, PBT is especially useful for training algorithms and neural network results that introduce new hyperparameters. It provides the possibility to find and develop more complex and powerful neural network models.
RAM/RFM Induction Heating Capacitors
RAM/RFM induction heating capacitors
RAM/RFM Induction Heating Capacitors,Water Pump Capacitor,Water Cooled Condense,Tank Capacitor,RAM/RFM Induction Heating Capacitors
YANGZHOU POSITIONING TECH CO., LTD. , https://www.cnfudatech.com