Linux file management introduces the way Linux manages files from the user's level. Linux has a tree structure to organize files. The top of the tree is the root directory (/), the node is the directory, and the leaf at the end is the file containing the data. When we give the full path of a file, we start from the root directory, go through each directory along the way, and finally reach the file.
We can perform many operations on files, such as opening and reading and writing. Among the commands related to Linux file management, we see many commands that operate on files. Most of them are based on the opening and reading and writing of files. For example, cat can open a file, read data, and finally display in the terminal:
$ cat test.txt
For programmers under Linux, understanding the underlying organization of the file system is necessary for in-depth system programming. Even ordinary Linux users can design better system maintenance solutions based on related content.
Storage device partition
The ultimate goal of the file system is to organize large amounts of data into persistent storage devices, such as hard disks and disks. These storage devices are different from internal memory. Their storage capacity is persistent and will not disappear due to power failure; the storage capacity is large, but the reading speed is slow.
Observe common storage devices. The initial area is MBR, which is used for Linux boot (refer to Linux boot). The remaining space may be divided into several partitions. Each partition has an associated partition table (Partition table), record the relevant information of the partition. This partition table is stored outside the partition. The partition table indicates the starting position of the corresponding partition and the size of the partition.

We often see partition C and partition D on Windows systems. There can also be multiple partitions under the Linux system, but they are all mounted on the same file system tree.
The data is stored in a partition. A typical Linux partition contains the following parts:
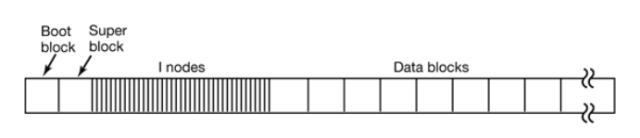
The first part of the partition is the boot block (Boot block), which is mainly for the computer boot service. After booting Linux, the MBR will be loaded first, and then the MBR will load the program from the boot area of ​​a certain hard disk. This program is responsible for the loading and startup of further operating systems. To facilitate management, even if no operating system is installed in a partition, Linux will reserve a boot area in the partition.
After the boot zone is the super block. It stores information about the file system, including the type of file system, the number of inodes, and the number of data blocks.
Followed by multiple inodes, they are the key to file storage. In the Linux system, a file can be divided into several data blocks for storage, just like Dragon Ball scattered around. In order to collect Qi Dragon Balls smoothly, we need a "radar" guide: the inode corresponding to this file. Each file corresponds to an inode. This inode contains multiple pointers to the various data blocks belonging to the file. When the operating system needs to read the file, it only needs to correspond to the "map" of the inode, collect the scattered data blocks, and we can harvest our files.

The last part is the data blocks that actually store the data.
inode introduction
Above we saw the macro structure of the storage device. We have to dive into the structure of the partition, especially how the files are stored in the partition.
A file is a division unit of data by a file system. The file system uses directories to organize files, giving files a hierarchical structure. The key to realizing this hierarchical structure on the hard disk is to use inodes to virtualize ordinary file and directory file objects.
In Linux file management, we know that in addition to its own data, a file also has ancillary information, that is, metadata of the file. This metadata is used to record many information about the file, such as file size, owner, group to which it belongs, modification date, etc. Metadata is not included in the file data, but is maintained by the operating system. In fact, this so-called metadata is included in the inode. We can use $ ls -l filename to view these metadata. As we saw above, the area occupied by the inode is different from the area of ​​the data block. Each inode is represented by a unique integer number (inode number).
In saving metadata, the inode is the key to the "file" from abstract to concrete. As mentioned in the previous section, inode storage consists of pointers to some data blocks in the storage device, and the contents of the file are stored in these data blocks. When Linux wants to open a file, it only needs to find the inode corresponding to the file, and then collect all the data blocks along the pointer to form the data of a file in memory.

The data blocks are at 1, 32, 0,…
Inode is not the only way to organize files. The easiest way to organize files is to put the files into the storage device in sequence, and DVD takes a similar approach. However, if there is a delete operation, the empty space caused by the deletion is mixed between normal files, which is difficult to use and manage.
A complicated way is to use a linked list. Each data block has a pointer to the next data block belonging to the same file. The advantage of this is that scattered free space can be used. The disadvantage is that the operation of the file must be performed in a linear manner. If you want random access, you must traverse the linked list until the target location. Since this traversal is not performed in memory, it is very slow.
The FAT system takes the pointer of the above linked list and puts it into an array in memory. In this way, FAT can quickly find a file based on the memory index. The main problem with this is that the size of the index array is the same as the total number of data blocks. Therefore, if the storage device is large, the index array will be relatively large.
Inode can make full use of space, occupying space in memory is not related to storage devices, and solves the above problem. But inode also has its own problems. The total number of data block pointers that each inode can store is fixed. If a file requires more data blocks than this total, the inode needs extra space to store the extra pointers.
inode example
In Linux, we find a file according to the directory file along the way by parsing the path. In addition to the file name, the entries in the directory also have corresponding inode numbers. When we enter $ cat /var/test.txt, Linux will find the inode number of the var directory file in the root directory file, and then synthesize the var data according to the inode. Then, according to the records in var, find the inode number of text.txt, collect data blocks along the pointer in inode, and synthesize the data of text.txt. Throughout the process, we refer to three inodes: the root directory file, the var directory file, and the inodes of the text.txt file.
Under Linux, you can use $ stat filename to query the inode number corresponding to a file.

In the storage device is actually stored as:
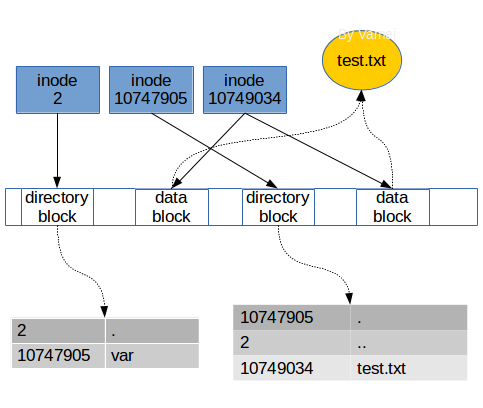
When we read a file, we actually find the inode number of the file in the directory, and then combine the data blocks according to the pointer of the inode and put it into memory for further processing. When we write a file, we assign a blank inode to the file, record the inode number in the directory to which the file belongs, and then select the blank data block, let the pointer of the inode point to these data blocks, and put it into memory Data.
File Sharing
In the process of Linux, when we open a file, it returns a file descriptor. This file descriptor is the subscript of an array, and the corresponding array element is a pointer. Interestingly, this pointer does not directly point to the file's inode, but points to a file table, and then through the table, points to the inode of the target file loaded into memory. As shown below, a process opened two files.
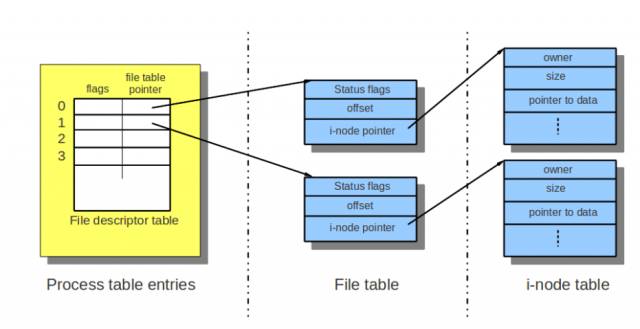
As you can see, each file table records the status of file opening (status flags), such as read-only, write, etc., and also records the current read-write position (offset) of each file. When two processes open the same file, there can be two file tables, and the corresponding open state and current position of each file table are different, thereby supporting some file sharing operations, such as simultaneous reading.
It should be noted that after the process forks, the child process will only copy the array of file descriptors, and share the file table and inode maintained by the kernel with the parent process. At this time, special care must be taken in writing the program.
to sum up
Here is a summary of the Linux file system. Linux uses inodes to make data into files.
Heating Pad For Feet,Heating Pad For Foot,Foot Heating Pad,Cordless Foot Warmer
Ningbo Sinco Industrial & Trading Co., Ltd. , https://www.newsinco.com