In recent years, research related to “natural language recognition based on neural networks†has made rapid progress, especially in terms of the textual representation of learning semantics. These advances have contributed to the creation of a series of truly novel products such as smart writing (Gmail's assistance (Email creation) and Talk to Books (link to the end of the text, try to talk to the book). It also helps to improve the performance of a variety of natural language tasks with a limited amount of training data, for example, building powerful text classifiers with just 100 tagged examples.
Below we will discuss two papers on the latest developments in Google Semantic Representation related research and two new models that can be downloaded on the TensorFlow Hub. We hope that developers will use these models to build exciting new applications.
TensorFlow Hub is a management tool for managing, distributing, and retrieving reusable code (models) for TensorFlow.
Semantic text similarity
In “Learning Semantic Textual Similarity from Conversationsâ€, we introduce a new method to learn the semantic form of semantic text similarity. It can be intuitively understood that if the responses of sentences have similar distributions, then they are semantically similar. For example, "How old are you?" and "What is your age?" are questions about age. You can answer them with a similar answer, such as "I'm 20 years old." (I am 20 years old). In contrast, although "How are you?" and "How old are you?" contain almost the same English words, their meanings are very different, so the answer is different.
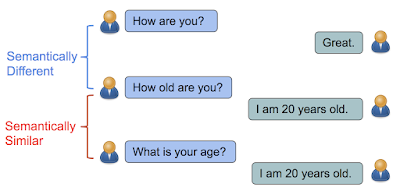
If sentences can be answered by the same answer, then they are semantically similar. Otherwise, they are semantically different.
In this study, our goal is to learn semantic similarity by answering classification tasks: Given a dialogue input, we hope to select the correct answer from a batch of randomly selected responses. However, the ultimate goal is to learn a model that can return codes that represent various natural language relationships, including similarity and relevance. By adding another predictive task (in this case the SNLI implied dataset) and enforced by the shared coding layer, we get better performance in terms of similarity measures, such as the STSBenchmark (Sentence Similarity Benchmark) and CQA tasks B (problem/question similarity task). This is because logic implications are very different from simple equivalences and are more conducive to learning complex semantic representations.

For a given input, the classification can be considered as a potential candidate ranking problem.
Universal Sentence Encoder
"Universal Sentence Encoder" introduces a model that extends the above multitasking training by adding more tasks. We use a model similar to skip-thought (the paper is linked at the end of the article) (it can be given Train sentences by predicting sentences within the text. However, although the encoder-decoder architecture was used in the original skip-thought model, we did not use it interchangeably. Instead, we used an encoder-only architecture to drive the prediction task by sharing the encoder. In this way, training time can be greatly shortened, while maintaining the performance of various transmission tasks, including emotion and semantic similarity classification. The goal is to provide a single encoder to support the widest possible range of applications including paraphrase detection, correlation, clustering, and custom text classification.
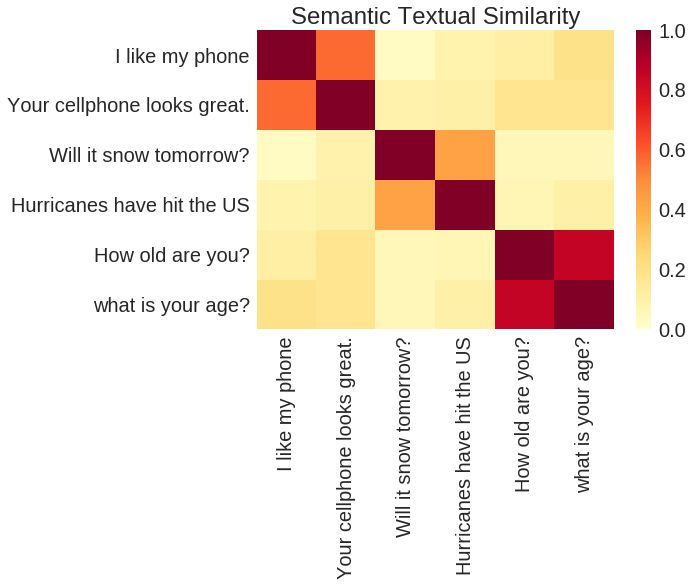
Based on the output of the TensorFlow Hub Universal Sentence Encoder, pairs of semantic similarities are compared.
As described in our paper, one version of the Universal Sentence Encoder model uses a Depth Averaged Network (DAN) encoder, while the other uses a more sophisticated self-service network architecture - Transformer.
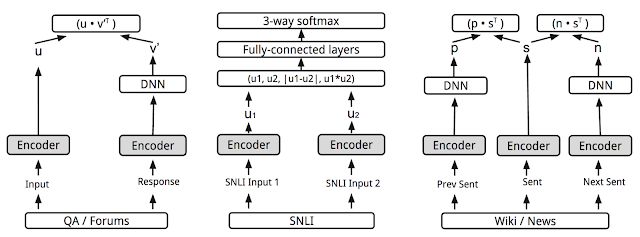
Multitasking training as described in "Universal Sentence Encoder." Various tasks and task structures are connected via shared encoder layers/parameters (gray boxes).
For more complex architectures, the model performs better on a variety of sentiment and similarity classification tasks than the relatively simple DAN model, while the short sentences are only slightly slower. However, as the length of the sentence increases, the computational time for using the Transformer model increases significantly, whereas under the same conditions, the computation time for the DAN model remains almost constant.
New model
In addition to the Universal Sentence Encoder model above, we will also share two new models on the TensorFlow Hub: Universal Sentence Encoder - Large and Universal Sentence Encoder - Lite. These are pre-trained Tensorflow models that return the semantic encoding of variable length text input. These codes can be used for the clustering of semantic similarity metrics, correlations, classifications, or natural language texts.
The Large model was trained using the Transformer encoder and our second paper was introduced. This model is suitable for scenarios that require high-precision semantic representation and require optimal model performance at the expense of speed and size.
The Lite model trains based on Sentence Piece vocabulary rather than words to significantly reduce vocabulary while vocabulary significantly affects model size. This model is suitable for scenarios with limited resources such as memory and CPU, such as device-side or browser-based implementations.
We are very pleased to share this research result and these models with the community. We believe that the results presented here are just a beginning, and there are many important research issues that need to be resolved. For example, extending the technology to more languages ​​(the above model currently only supports English). We also hope to further develop this technology so that we can understand paragraphs and even document-level texts. If we can accomplish these tasks, perhaps we can create a truly "universal" encoder.
Laptop Stand Macbook Air,Laptop Stand Macbook Air Black,Laptop Stand Macbook Pro Vertical,Laptop Stand Macbook Travel,etc.
Shenzhen Chengrong Technology Co.ltd is a high-quality enterprise specializing in metal stamping and CNC production for 12 years. The company mainly aims at the R&D, production and sales of Notebook Laptop Stands and Mobile Phone Stands. From the mold design and processing to machining and product surface oxidation, spraying treatment etc ,integration can fully meet the various processing needs of customers. Have a complete and scientific quality management system, strength and product quality are recognized and trusted by the industry, to meet changing economic and social needs .

Laptop Stand Macbook Air,Laptop Stand Macbook Air Black,Laptop Stand Macbook Pro Vertical,Laptop Stand Macbook Travel
Shenzhen ChengRong Technology Co.,Ltd. , https://www.laptopstandsupplier.com