Parallel computing model usually refers to the design and analysis of parallel algorithms, and abstracts the basic features of various parallel computers (at least one kind of parallel computer) to form an abstract computing model.
PRAM modelThe PRAM (Parallel Random Access Machine) model, also known as the shared memory SIMD model, is an abstract parallel computing model that is developed directly from the serial RAM model. In this model, it is assumed that there is an infinitely large shared memory, there are a finite number or an infinite number of processors with the same function, and they all have simple arithmetic operations and logic judgment functions. Each processor can pass at any time. Shared storage units interact with each other. According to the limitation that the processor reads and writes simultaneously in the shared memory unit, the PRAM model can be divided into the following types:
The Exclusive-Read and Exclusive-Write PRAM model is not allowed, abbreviated as PRAM-EREW;
A PRAM model that allows simultaneous read but not concurrent write (PRAM-CREW);
Concurrent-Read and Concurrent-Write PRAM models are allowed, abbreviated as PRAM-CRCW.
Obviously, it is unrealistic to allow writing at the same time. Therefore, the PRAM-CRCW model was further agreed upon, and the following models were formed:
Only allow all processors to write the same number at the same time, this time is called common PRAM-CRCW, abbreviated as CPRAM-CRCW;
Only the highest priority processor is allowed to write first, this time is called Priority PRAM-CRCW, abbreviated as PPRAM-CRCW;
Allows any processor to write freely, this time called Arbitrary PRAM-CRCW, abbreviated as APRAM-CRCW.
The actual content written to the memory is the sum of the numbers written by all processors. The PRAM-CRCE called Sum at this time will be referred to as SPRAM-CRCW.

PRAM model advantages
The PRAM model is particularly suitable for the expression, analysis, and comparison of parallel algorithms. It is simple to use and many of the underlying details about parallel computers, such as inter-processor communication, storage system management, and process synchronization, are implicit in the model; it is easy to design algorithms and Modifications can be run on different parallel computer systems; depending on the needs, something like considerations such as synchronization and communication can be added to the PRAM model.
The disadvantages of the PRAM model
(1) A global shared memory is used in the model, and the local storage capacity is small enough to describe the performance bottleneck of distributed main memory multiprocessors. The assumption of sharing a single memory is obviously not suitable for MIMD machines with distributed storage structures.
(2) The PRAM model is synchronous, which means that all instructions are operated in a lock-step manner. Although users do not feel the existence of synchronization, the existence of synchronization is indeed time-consuming and does not reflect the reality of many systems. Asynchronous;
(3) The PRAM model assumes that each processor can access any unit of shared memory in a unit of time. Therefore, there is no delay, unlimited bandwidth, and no overhead for inter-processor communications. It is assumed that each processor can access every unit of time. It is unrealistic for any storage unit to omit actual, reasonable details, such as resource competition and limited bandwidth;
(4) The PRAM model assumes that the processor is limited or infinite, and there is no overhead for the increase of parallel tasks;
(5) Failed to describe the threading technique and the pipeline prefetching technique, which are the most common techniques used in today's parallel architectures.
BSP modelThe basic principle of BSP model
The BSP model is an asynchronous MIMD-DM model (DM: distributed memory, SM: shared memory). The BSP model supports messaging systems, asynchronous parallel blocks, and explicit synchronization between blocks. The model is based on a master coordination, all workers With lock-step execution, data is read from the input queue. The architecture of the model is shown in the figure:
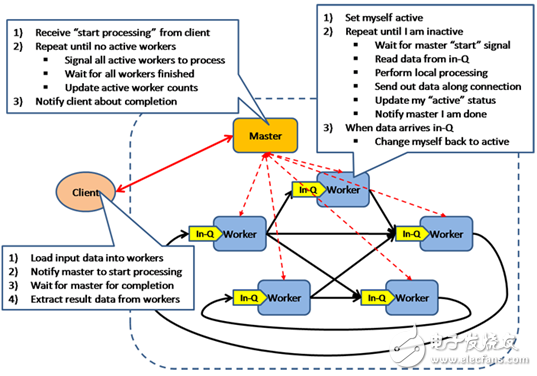
In addition, BSP parallel computing model can be described with 4 parameters of p/s/g/I:
P is the number of processors (with memory).
s is the calculation speed of the processor.
g is the number of local computing operations per second/the number of bytes transmitted per second by the communication network, which is referred to as a router throughput rate, and is regarded as a bandwidth step (time steps/packet)=1/bandwidth.
i is the global synchronization time cost, which is referred to as the time between global synchronization (Barrier synchronization time).
Suppose there are p processors transmitting h bytes of information at the same time, then gh is the communication overhead. Synchronization and communication overhead are normalized to the specified number of processors.
The BSP calculation model is not only an architectural model but also a method for designing parallel programs. The BSP programming guidelines are bulk synchrony and their uniqueness lies in the introduction of the superstep concept. A BSP program has both horizontal and vertical structures. From a vertical perspective, a BSP program consists of a series of serial supersteps, as shown in the figure:
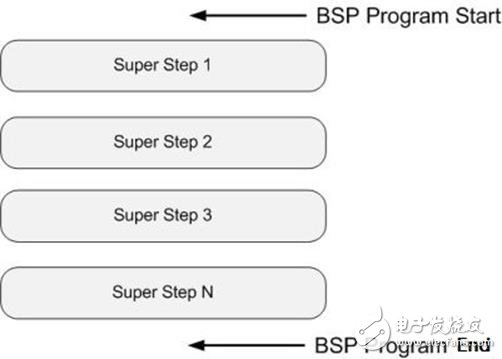
This structure is similar to a serial program structure. From a horizontal perspective, in an overstep, all processes perform local calculations in parallel. An overstep can be divided into three phases as shown in the figure:
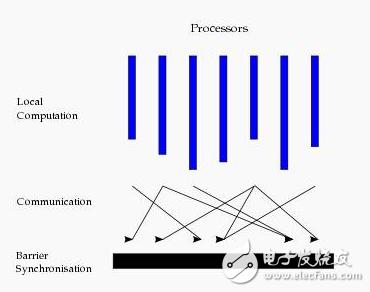
In the local computing phase, each processor only performs local calculations on the data stored in the local memory.
The global communication phase operates on any non-local data.
The fence synchronization phase waits for the end of all communication activities.
BSP model features
1. The BSP model divides the calculation into one superstep, effectively avoiding deadlocks.
2. It separates processors from routers, emphasizing the separation of computing tasks and communication tasks, while routers only perform point-to-point messaging without providing functions such as composition, replication, and broadcasting. This not only masks the specific Internet. Topology also simplifies the communication protocol;
3. The global synchronization implemented in hardware using barrier synchronization is at a controllable coarse-grained level, thus providing an efficient way to implement tightly-coupled synchronous parallel algorithms, without the programmer being overburdened;
4. When analyzing the performance of the BSP model, it is assumed that local operations can be completed in one time step, and in each super step, one processor sends or receives at most h messages (called h-relation). Assume that s is the transmission establishment time, so the time for transmitting h messages is gh+s, and if so, L should be at least equal to gh. It is clear that the hardware can set the L as small as possible (for example, using pipelining or large communication bandwidth to make g as small as possible), and the software can set the upper limit of L (since L is larger, the parallel granularity is larger). In actual use, g can be defined as the ratio of the number of local calculations that the processor can perform per second and the amount of data that can be transmitted by the router per second. If the proper calculation and communication can be balanced, then the BSP model has major advantages in programmability, and executing the algorithm directly on the BSP model (not automatically compiling them), this advantage will be more obvious with the increase of g;
5. Algorithms designed for the PRAM model can all be implemented by emulating some PRAM processors on each BSP processor.
Evaluation of BSP model
1. In parallel computing, Valiant tried to build a bridge between software and hardware similar to the von Neumann machine. It demonstrated that the BSP model can play such a role. Because of this, the BSP model is also often Called bridge model.
2. In general, the programmability of distributed-stored MIMD models is poor, but in the BSP model, if computing and communication can be properly balanced (eg, g=1), then it presents a major advantage in terms of programmability. .
3. On the BSP model, some important algorithms (such as matrix multiplication, parallel preordering, FFT, and sorting) have been implemented directly. They all avoid the overhead of automatic storage management.
4. The BSP model can be effectively implemented on the hypercube network and the optical cross-switch interconnection technology. It shows that the model has nothing to do with the specific technology implementation, as long as the router has a certain communication throughput rate.
5. In the BSP model, the length of the superstep must be able to adequately adapt to any h-relation, which is what people most dislike.
6. In the BSP model, messages sent at the start of a superstep can be used only at the next superstep even if the network delay time is shorter than the length of the superstep.
7. Global barriers in the BSP model The synchronization assumption is supported with special hardware, but many parallel machines may not have corresponding hardware.
Comparison between BSP and MapReduce
Execution mechanism: MapReduce is a data flow model. Each task only processes the input data, and the output data generated is used as the input data of another task. The parallel tasks are performed independently and the serial tasks are copied between the disk and the data. As an exchange medium and interface.
The BSP is a state model. Each subtask performs operations such as calculating, communicating, and modifying the state of the graph on the local subgraph data. The parallel tasks exchange intermediate calculation results through message communication and do not need to copy the entire data like MapReduce. .
Iterative processing: The MapReduce model theoretically requires several operations to be started in succession to complete the iterative processing of the graph, and all data is exchanged between adjacent operations through a distributed file system. The BSP model only initiates a single job. Iterative processing can be accomplished using multiple super-steps, and the intermediate calculation results are passed between the two iterations through the message. Due to reduced job startup, scheduling overhead, and disk access overhead, the BSP model is more efficient in iterative execution.
Data segmentation: Based on the graph processing model of BSP, it is necessary to redistribute the loaded graph data once to determine the route address during message communication. For example, during the parallel loading of data by tasks, according to a certain mapping strategy, the read data is redistributed to the corresponding computing task (usually in memory), with both disk I/O and network communication. Great. However, a BSP job requires only one data segmentation. In addition to the message communication in the subsequent iterative calculation process, no data migration is required. MapReduce-based graph processing model, in general, does not require special data segmentation processing. However, the Shuffle process with intermediate results in the Map and Reduce stages increases disk I/O and network communication overhead.
MapReduce was originally designed to solve large-scale, non-real-time data processing problems. "Large-scale" decision-making data has local characteristics that can be used (and thus can be divided) and can be processed in batches; "non-real-time" represents that the response time can be longer and there is sufficient time to execute the program. The BSP model has excellent performance in real-time processing. This is the biggest difference between the two.
The realization of BSP model
1.Pregel
Google's large-scale graph computing framework first proposed applying the BSP model to graph calculations. For details, see Pregel, a large-scale graph processing system. However, it has not been open source yet.
2.Apache Giraph
The ASF community's Incubator project, contributed by Yahoo!, is the BSP's Java implementation, focusing on iterative graph calculations (such as pagerank, shortest joins, etc.), where each job is a hadoop job without a reducer process.
3.Apache Hama
It is also the Incubator project of the ASF community. Unlike Giraph, it is a pure Java implementation of the BSP model and is not only used for graph calculations. It is intended to provide a generic BSP model application framework.
4.GraphLab
An iterative graph calculation framework of CMU, a BSP model application framework implemented in C++, but with some modifications to the BSP model. For example, after each step, the global synchronization point is not set, and calculations can be performed completely asynchronously, accelerating the task. Complete time.
5.Spark
An application framework focused on iterative computing implemented at the University of California, Berkeley, written in Scala, proposed the concept of an RDD (Elastic Distributed Data Set), where each step of the computational data was streamlined from the previous step and greatly reduced Network transmission, while ensuring the integrity of the pedigree (that is, errors can only return to the previous step), enhanced fault tolerance. The Spark paper also implements the BSP model (called Bagel) based on this framework. It is worth mentioning that the domestic watercress is also based on this idea to achieve such a framework called Dpark in Python, and has been open source. Https://github.com/douban/dpark
6.Trinity
This is a Microsoft figure computing platform developed by C#. It is intended to provide a dedicated graphics computing application platform, including the underlying storage to the upper application. It should be possible to implement the BSP model. The article is sent on SIGMOD13. It is hateful. It is not open source. Homepage
7.GoldenOrb
The other Java implementation of the BSP model is an open source implementation of Pregel, used on hadoop.
Website: (To FQ)
Source code: https://github.com/jzachr/goldenorb
8.Phoebus
The BSP model implemented in the Erlang language is also an open source implementation of Pregel. Https://github.com/xslogic/phoebus
9. Rubicon
Pregel's open source implementation. Https://launchpad.net/rubicon
10.Signal/Collect
It is also a Scala version of the BSP model implementation.
11.PEGASUS
A Java version of the BSP model implemented on Hadoop was published on SIGKDD2011. ~pegasus/index.htm
LogP modelAccording to the trend of technological development, one of the mainstreams of the development of parallel computers in the late 1990s and in the future was the massive parallel machine, namely MPC (Massively Parallel Computers), which consisted of thousands of powerful processor/memory nodes. An interconnected network with limited bandwidth and considerable delay constitutes. Therefore, we must take this situation into full consideration when building a parallel computing model, so that the parallel algorithm based on the model can run effectively on existing and future parallel computers. According to the existing programming experience, the existing programming methods such as shared memory, message passing, and data parallelism are popular, but there is not yet a recognized and dominant programming method. Therefore, it should be pursued independently of the above programming methods. The calculation model. According to the existing theoretical model, the shared storage PRAM model and the SIMD model of the interconnection network are not suitable for the development of parallel algorithms because they do not include the situation of distributed storage, nor do they take into account actual factors such as communication and synchronization, and thus cannot Accurately reflecting the behavior of algorithms running on real parallel computers, so in 1993 D. Culer et al., on the basis of analyzing the characteristics of distributed storage computers, proposed a multi-computer model of point-to-point communication, which fully explained the interconnection. The performance characteristics of the network do not relate to the specific network structure, nor do they assume that the algorithm must be described with realistic messaging operations.
The LogP model is a distributed, point-to-point communication multiprocessor model in which the communication network is described by four main parameters:
(1) L (Latency) Indicates the upper limit of the waiting or delay time required for the message (one or several words) of the source processor and the destination processor to communicate, indicating the delay of the message in the network.
(2) o (overhead) Indicates the time spent by the processor in preparing to send or receive each message (including the operating system core overhead and network software overhead). During this time, processing cannot perform other operations.
(3) g (gap) indicates the minimum time interval for a processor to send or receive messages twice in a row. The reciprocal is the communication bandwidth of the microprocessor.
(4) Number of Processor Processor/Memory Modules
Assuming that one cycle completes a local operation and is defined as a time unit, then L, o, and g can all be expressed as integer multiples of the processor cycle.
LogP model features
(1) Seize the performance bottleneck between the network and the processor. g reflects the communication bandwidth. Up to L/g messages per unit time can be transmitted between processors.
(2) The processors work asynchronously, and synchronization is accomplished through message transfer between processors.
(3) Some reflection on multi-threading technology. Each physical processor can simulate multiple virtual processors (VPs). When a VP has an access request, the calculation will not be terminated, but the number of VPs is limited by the communication bandwidth and the overhead of context switching. VP is limited by the network capacity and there are at most L/g VPs.
(4) The message delay is uncertain, but the delay is not greater than L. The waiting time experienced by the message is unpredictable, but in the absence of congestion, the maximum is no more than L.
(5) LogP model encourages programmers to adopt some good strategies, such as job assignment, calculation and communication overlap, and balanced communication mode.
(6) The actual running time of the algorithm can be estimated.
The inadequacies of the LogP model
(1) The description of the communication mode in the network is not deep enough. For example, retransmission messages may occupy full bandwidth, intermediate router cache saturation, etc. are not described.
(2) The LogP model is mainly applicable to message delivery algorithm design. For the shared storage model, it is simply assumed that the remote read operation is equivalent to two message transmissions, and the pipeline prefetch technique, data inconsistency caused by the cache, and the cache hit rate are not considered. The impact on the calculation.
(3) Does not consider the contextual overhead of multi-threading techniques.
The unique flat cable shape allows for a cleaner and safer installation. You can easily and seamlessly make the cable run along walls, follow edges&corners or even make it completely invisible by sliding it under a carpet.

Flat patch cable include cat8 flat patch cable, cat7 flat patch cable, cat6 flat patch cable and CAT5E Flat Patch Cable.
CAT8 patch cable Support bandwidth up to 2000MHz & transmitting data at speeds of up to 40Gbps,connect to LAN/WAN segments and networking gear at maximum speed.
CAT7 cable Support bandwidth up to 1000MHz & transmitting data at speeds of up to 10Gbps,connect to LAN/WAN segments and networking gear at maximum speed.
CAT6 Flat Ethernet Cable provides high performance, as it uses 250Mhz to transfer data up to 1Gbps, faster than CAT5E. Allowing for greater bandwidth and, therefore, home and office productivity.
CAT5e cable Support bandwidth up to 100MHz & transmitting data at speeds of up to 1000bps,connect to LAN/WAN segments and networking gear at maximum speed.
Flat Cable,Flat Extension Cord,Flat Ribbon Cable,Flexible Flat Cable
Shenzhen Kingwire Electronics Co., Ltd. , https://www.kingwires.com